

In this article I am going to try to explain to you everything you need to know about bean mapping in Java. Before doing so let’s first understand why and when mapping objects is necessary.
It’s 2021 already and I was wondering how much does the software design has changed the last 20 years?
Martin Fowler in "Patterns of Enterprise Application Architecture" mentions the "Data Transfer Object" design pattern. Fowler defines the pattern as such: "An object that carries data between processes in order to reduce the number of method calls".
This pattern essentially advocates that when the communication between processes is expensive then it is preferable to avoid the communication overhead by sending all the required data in advance, in an effort to reduce this overhead.
To achieve this one may create aggregate objects that contain all the required information to be sent. These objects are called Data Transfer Objects or more commonly DTO.
Fowler mentions "Usually an assembler is used on the server side to transfer data between the DTO and any domain objects".
The assembler’s (a.k.a. mapper) purpose is to compose the DTOs given all the domain models that contain all the data to be transmitted.
Were they ever relevant? The answer is maybe, it depends…
Developers working on enterprise applications and especially with Java are overzealous, they try to abstract everything creating layers and layers of abstraction.
Furthermore, they strive to separate every single business part in a different module in order to achieve separation of concerns and loose coupling between the components of the code.
This some times works well and the outcome is a robust future-proof application but other times is just a sad example of over-engineering.
Let’s see a more concrete example.
In a typical application, the application will have to communicate with external entities, i.e. with a user by providing some sort of user interface or with another system by providing or consuming an API etc. So, for this case the input and output will consist of presentation models or DTO etc.
Then, the application will have to process in some way the received information or the information to transmit according to the business logic. This layer will usually have it’s own representation of the business models.
Finally, it will be required to persist or fetch some data from/to the database. There will be some "entity" objects that represent in an object oriented fashion the data persisted in the database layer (based on the repository pattern).
So, in a typical 3-layer application we can count 3 different types of models:
Repository models/entities
Business models
Presentation models or DTOs
Now you will most probably think that at minimum we will need 3 kind of objects in our applications. However, no. As I have said it depends!
We can actually use only one Class in our code to represent everything.
Having just one class for each layer may work OK for a small application or if we want to write an application fast, let’s say some proof of concept.
Not having to deal with mapping and other boilerplate code will keep things simple and improvements may come in future iterations of the development process when and only if they are needed.
Actually, Spring’s Data Rest extension in a sense it does just that. Someone will have to create only the entities and all the other layers will be based on these (with some automagic being involved in the process).
Let’s focus more on the benefits of using DTO though. This way it will become more apparent when to use them or not.
Let me give you a real life example. A few years back I was working on an electronic restaurant menu which was optimized to work on tablets with potentially slow internet connection.
Our approach was to download all the content of the catalog in all the available languages once and cache it in the browser.
For that reason we constructed an uber DTO which contained all the information of the catalog and actually we were caching it in the server side too. You see, the catalogs were read most often than modified.
Have in mind that this is a case where we knew that all the information should be eventually transferred to the client.
There are cases where we want to remove part of the information our business model contains. An example is a "user" object which contains some password or security question.
public class User { private String username; private String password; private String securityAnswer; /* ...code and stuff... */ }
It seems appropriate never to transmit this information. A DTO which doesn’t include these fields may be used.
public class UserDTO { private String username; /* ...code and stuff... */ }
Note that if we serialize our object to JSON, XML or some other representation the serializer may support configuration for hiding fields etc.
public class User { private String username; @JsonIgnore private String password; @JsonIgnore private String securityAnswer; /* ...code and stuff... */ }
However, DTO is more generic and can be used regardless representation, protocols etc.
Reduction is useful to create "light" representations of our objects too. In opposition to the first argument where we want eagerly to transfer information we may want to use a lazy approach.
An example would be to list all the posts of a blog. A DTO could contain only the first X characters of each article and the title. If and when clicked another DTO representation of the article could be returned by a subsequent communication and return the whole text along side with the comments and other information.
Finally, another case where data reduction is handy is to avoid complex representation
cases. For example two objects that are creating a cycle in the object graph,
would not be converted to JSON. However, a DTO could represent this relationship
partially and avoid this issue when converting it to JSON (of course
the same can be achieved with @JsonIgnore but you get my point).
Another capability offered by DTO pattern is to adapt the provided data. Let’s say that we have a user and in our business model we have a birth date field.
public class User { private String username; private LocalDate birthday; /* ...code and stuff... */ }
However, in our DTO we want to expose an age field. This can be done quite easily.
public class UserDTO { private String username; private Integer age; /* ...code and stuff... */ }
As I have mentioned previously enterprise developers love to separate their code into modules and layers. It is important each module or layer to be isolated by the other ones.
The isolation among other things ensures that implementation details are not leaked outside the module/layer and the code is decoupled in a way that change in one module/layer should not affect the other ones.
DTO and different types of models per module/layer contribute towards code decoupling.
I have made such an extensive reference to DTO because mappers are historically associated with this particular pattern.
Let’s say we have the following business model.
class User { String username; String email; String password; String salt; LocalDate created; Boolean activated; Boolean locked; //... getters and setters }
And we want to map it to the following DTO.
class UserDTO { enum Status { ACTIVATED, LOCKED, NEW } String username; String email; LocalDate creationTs; Status status; //... getters and setters }
A mapper could look like this:
class Mapper { static UserDTO userToDto(User user) { UserDTO dto = new UserDTO(); dto.setUsername(user.getUsername()); dto.setEmail(user.getEmail()); dto.setCreationTs(user.getCreated()); if (user.getLocked) { dto.setStatus(Status.LOCKED); } else if (user.getActivated) { dto.setStatus(Status.ACTIVATED); } else { dto.setStatus(Status.NEW); } return dto; } }
The benefit at a first glance may not be apparent but we have managed to contain all the knowledge about how the mapping should be done within the Mapper.
The business layer which uses the User class won’t change if the UserDTO changes somehow, let’s say renamed the username field to handle. In that case only the Mapper code should be updated and of course the code which uses the DTO which should be in the presentation layer.
Fowler in 2004 argued that the DTO pattern shouldn’t be used if not actually needed. He has specifically mentioned that code decoupling locally inside the same application is not a good enough reason especially because of the overhead that exists regarding the creation and maintenance of all the mappers.
However, this overhead nowadays is minimized because there are plenty of tools which automate this process.
In the next sections we are going to see which are the available tools in Java nowadays, how they work under the hood and how they compare in terms or performance.
There are 3 basic mechanisms that are used by the various mapping frameworks in Java in order to automate this process.
Reflection
Code generation
Byte-code instrumentation
I am going to talk more about each methodology below and present some example code.
|
|
Mind that the example code is written only for demonstration purposes and offers very trivial functionality. Do not use it in production, instead use one of the many well established mapping frameworks out there like the ones mentioned later in this article. |
Reflection is a powerful technique that allows to manipulate in various ways an object at runtime. It is the most dynamic methodology but it comes with a considerable price, it is the slowest one.
Let’s assume that we want to map two objects by mapping their fields if their names and types are equal.
This could be done with reflection like that:
public static <T> T map(Object src, Class<T> c) throws NoSuchMethodException, InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException { if (src == null) { return null; } Constructor<T> defaultPublicConstructor = c.getConstructor(); T targetObject = defaultPublicConstructor.newInstance(); Field[] srcFields = src.getClass().getDeclaredFields(); for (Field srcField : srcFields) { try { Field trgField = targetObject.getClass().getDeclaredField(srcField.getName()); srcField.setAccessible(true); trgField.setAccessible(true); trgField.set(targetObject, srcField.get(src)); } catch (NoSuchFieldException ex) { System.out.println(String .format("Field %s not found on target class", srcField.getName())); } } return targetObject; }
In the above example the map method accepts as an argument the src object and the target class. It creates a target object and populates the fields even if they are declared private and are not exposed by a getter method.
The mapper do not need to know beforehand which classes it will map. It can even map classes that are loaded at runtime.
Can map private members
Can map classes that were loaded at runtime
From a user’s perspective a default mapper with sane assumptions is very easy to use with minimal code
From an implementor’s perspective it is relatively easy to implement and debug too
It is significantly slow based on the other methodologies
There may be unexpected runtime behavior and security considerations
The reflection support may be disabled
Next to our list is code generation. This is the generation of source code that performs the mapping similarly to a hand written mapper when the application is compiled.
To do so the most popular way would be to create a special annotation that marks interfaces as mappers, create an interface with the methods that we wish to use for the mapping and let an annotation processor create the mapping interface’s implementation at the compilation of the program.
Such a mapper could seem like that.
@Target(ElementType.TYPE) @Retention(RetentionPolicy.SOURCE) public @interface Mapper { }
This is client side code.
@Mapper public interface StaticCodeGenerationMapper { StaticCodeGenerationMapper INSTANCE = Mappers.getMappers(StaticCodeGenerationMapper.class); TargetBean map(SourceBean s); }
@SupportedAnnotationTypes( "masterex.github.com.customstaticcodegenerationmapper.Mapper") @SupportedSourceVersion(SourceVersion.RELEASE_11) @AutoService(Processor.class) public class MapperGenerator extends AbstractProcessor { @Override public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment re) { List<Element> annotatedElements = annotations.stream() .flatMap(annotation -> re.getElementsAnnotatedWith(annotation).stream()) .filter(x -> x.getKind() == ElementKind.INTERFACE) .collect(Collectors.toList()); annotatedElements.stream() .forEach(this::createImplementation); return false; } private void createImplementation(Element element) { String implementationClassName = String.format("%s%s", element.getSimpleName().toString(), SUFFIX); String interfaceQualifiedName = ((TypeElement) element).getQualifiedName().toString(); String packageName = interfaceQualifiedName.substring(0, interfaceQualifiedName .lastIndexOf('.')); try { JavaFileObject mapperFile = processingEnv.getFiler(). createSourceFile(packageName + "." + implementationClassName); try (PrintWriter out = new PrintWriter(mapperFile.openWriter())) { if (packageName != null) { out.print("package "); out.print(packageName); out.println(";"); out.println(); } out.print("public class "); out.print(implementationClassName); out.print(" implements " + interfaceQualifiedName); out.println(" {"); out.println(); element.getEnclosedElements().stream() .filter(e -> e.getKind() == ElementKind.METHOD) .forEach(e -> generateMethod(e, out)); out.println("}"); } } catch (IOException ex) { throw new RuntimeException("Failed to generate mapper", ex); } } private void generateMethod(Element element, PrintWriter out) { TypeMirror srcType = ((ExecutableType) element.asType()).getParameterTypes().get(0); TypeMirror destType = ((ExecutableType) element.asType()).getReturnType(); out.println(" @Override"); out.println(String.format(" public %s %s(%s src) {", destType, element .getSimpleName(), srcType)); out.println(" if (src == null) {"); out.println(" return null;"); out.println(" }"); out.println(String.format(" %s dst = new %s();", destType, destType)); DeclaredType srcDeclaredType = (DeclaredType) srcType; List<Element> srcMethods = srcDeclaredType.asElement().getEnclosedElements().stream() .filter(e -> e.getKind() == ElementKind.METHOD) .filter(e -> e.getSimpleName().toString().startsWith("get")) .collect(Collectors.toList()); DeclaredType destDeclaredType = (DeclaredType) destType; Set<String> dstMethods = destDeclaredType.asElement().getEnclosedElements().stream() .filter(e -> e.getKind() == ElementKind.METHOD) .filter(e -> e.getSimpleName().toString().startsWith("set")) .map(e -> e.getSimpleName().toString()) .collect(Collectors.toSet()); srcMethods.stream() .filter(method -> dstMethods.contains(method.getSimpleName().toString() .replaceFirst("g", "s"))) .forEach(method -> { out.println(String.format(" dst.%s(src.%s);", method.getSimpleName().toString().replaceFirst("g", "s"), method)); }); out.println(" return dst;"); out.println(" }"); } }
The above code uses Google Autoservice library which facilitates the creation of annotation processors.
As you can see the implementation of the client is a little more demanding than the previous one. The developer should create an interface with the methods required for the mapping to work.
The processor scans the client’s code for interfaces annotated with this specific annotation and for each one found it goes on with the creation of the actual mapper implementation. A name for the class implementation is selected based on the interface name concatenated with the word Implementation.
In the above example the mapping is pretty naive. It maps the setters of the destination object with the getters of the target’s one. It assumes that the ones that have the same name are also of the same type.
Literally the generated file is created by writing line per line its content.
Mind that in order to get at runtime the actual implementation of the generated mapper a trick is required:
StaticCodeGenerationMapper INSTANCE = Mappers.getMappers(StaticCodeGenerationMapper.class);
The Mappers class is implemented by the mapping framework and uses a
bit of reflection in order to return an object that implements our mapper’s
interface. This is essential because the concrete class does not actually exist
when we write the client code. Let’s see it:
public static <T> T getMappers(Class<T> c) { try { Constructor<T> constructor = (Constructor<T>) c.getClassLoader() .loadClass(c.getName() + SUFFIX).getDeclaredConstructor(); constructor.setAccessible(true); return constructor.newInstance(); } catch (ClassNotFoundException | NoSuchMethodException | SecurityException | InstantiationException | InvocationTargetException | IllegalAccessException ex) { throw new RuntimeException(ex); } }
Performance comparable to a hand written mapper
Except the part of the reflective loading of the concrete implementation there is no need for other runtime dependencies
From a user’s perspective debugging the mapper or understanding how it works is pretty easy
If required one may copy the generated mappers into the project and eliminate the need of external dependencies (including the need of loading the mapper with reflection)
These mappers cannot map what they don’t know! No mapping of objects loaded at runtime (which do not at least implement an existing interface)
No way of mapping private members
Requires a bit more code from the client’s implementation side
The mapper implementation is more complex and more difficult to achieve/debug
More mapping methods means a bigger generated file
This is the process of generating bytecode at runtime.
In a sense, it is pretty similar to the static code generation. It creates new methods that can handle the mapping but instead of writing them as java text in a file, it writes them as bytecode.
Below there is an example offering similar functionality as the static code generated mapper.
public interface AbstractMapper<S, D> { public D map(S o); }
public class InstrumentationMapper<S, D> { private AbstractMapper<S, D> mapper; public InstrumentationMapper(final Class<S> source, final Class<D> destination) { try { this.mapper = getMapper(source, destination); } catch (InstantiationException | IllegalAccessException | NoSuchMethodException | IllegalArgumentException | InvocationTargetException ex) { throw new RuntimeException("Failed to initialize mapper", ex); } } public D map(S source) { return mapper.map(source); } private synchronized AbstractMapper<S, D> getMapper(final Class<S> source, final Class<D> destination) throws InstantiationException, IllegalAccessException, NoSuchMethodException, IllegalArgumentException, InvocationTargetException { String mapperClassName = (source.getName() + destination.getName()) .replaceAll("\\.", ""); try { return (AbstractMapper<S, D>) destination.getClassLoader() .loadClass(mapperClassName).getDeclaredConstructor().newInstance(); } catch (ClassNotFoundException e) { return (AbstractMapper<S, D>) generateMapper(destination.getClassLoader(), mapperClassName, source, destination) .getDeclaredConstructor().newInstance(); } } private Class<?> generateMapper(ClassLoader classLoader, String className, final Class<S> source, inal Class<D> destination) { try { ClassPool cp = ClassPool.getDefault(); CtClass cc = cp.makeClass(className); cc.setInterfaces(new CtClass[]{cp.get(AbstractMapper.class.getName())}); CtNewConstructor.defaultConstructor(cc); CtClass returnType = cp.get(Object.class.getName()); CtClass[] arguments = new CtClass[]{cp.get(Object.class.getName())}; CtMethod ctMethod = new CtMethod(returnType, "map", arguments, cc); ctMethod.setBody(mappingMethodBody(source, destination)); cc.addMethod(ctMethod); cc.setModifiers(cc.getModifiers() & ~Modifier.ABSTRACT); Class<?> generetedClass = cc.toClass(); return generetedClass; } catch (NotFoundException | CannotCompileException ex) { Logger.getLogger(InstrumentationMapper.class.getName()).log(Level.SEVERE, null, ex); } throw new RuntimeException("Failed to generate mapper."); } private String mappingMethodBody(final Class<S> src, final Class<D> destination) { StringBuilder sb = new StringBuilder(); sb.append("{").append(String.format("%s dst = new %s();", destination.getName(), destination.getName())); sb.append(String.format("%s src = (%s) $1;", src.getName(), src.getName())); Method[] srcMethods = src.getDeclaredMethods(); for (Method srcMethod : srcMethods) { if (!srcMethod.getName().startsWith("get")) { continue; } try { Method trgMethod = destination.getMethod(srcMethod.getName() .replaceFirst("get", "set"), srcMethod.getReturnType()); sb.append(String .format("dst.%s(src.%s());", trgMethod.getName(), srcMethod.getName())); } catch (NoSuchMethodException | SecurityException ex) { System.out.println(String .format("Method %s not found or accessible on source or target class", ex)); } } sb.append("return dst;").append("}"); return sb.toString(); } }
Such a mapper would be created like that from within our program:
InstrumentationMapper<SourceBean, TargetBean> mapper = new InstrumentationMapper<>(SourceBean.class, TargetBean.class);
The above code uses the Javassist library for the bytecode manipulation part.
First of all we create an interface which offers a map method. This accepts an object of one type and return an object of a different type.
Next, the InstrumentationMapper will create at runtime a class which
implements the interface mentioned above. It uses a bit of reflection in
order to examine the classes that will map and based on that it creates
the implementation.
The reflection is used only when the mapper is created. Afterwards, the mapper should perform in theory as a hand written one.
The tricky part in InstrumentationMapper is that at runtime the generics
are erased. So, the generated bytecode class and methods have to take
that into account.
Performance comparable to hand written mappers after the initialization
Can handle objects loaded at runtime
From a user’s perspective a default mapper with sane assumptions is very easy to be used with minimal code
Probably brings the best of both the previous approaches
Cannot map private members (without alerting the bytecode of the mapped classes or using reflection)
From a user’s perspective debugging such a mapper if required is tricky
Implementing and debugging the mapper is complex
Higher initialization overhead
As it depends on reflection at runtime for the creation of the mappers it may suffer from the relevant limitations mentioned before
Now that we have a better understanding about how automated mapping in Java works we can imagine what are the limitations and the strengths of each framework based on how they work under the hood.
A few traits of the frameworks are strongly connected to the methodology it uses.
First of all the performance, meaning how fast it can map one object to another. Then, another important characteristic is if it can dynamically handle objects loaded at runtime or not.
Additionally, apart from the simple conventional cases I have presented in the examples earlier, most mappers accept additional configuration regarding what fields to map and how to do it.
Each framework approaches this configuration differently. Most common ways are to express these mapping rules in code by exposing some API, in annotations in the mapped classes or in XML. The expressiveness of the API a mapping framework provides is another important factor which deeply affects the day to day productivity of the development process.
Finally, another aspect of a framework is if it can change the mapping configuration it uses without the need of recompilation or even change the configuration at runtime.
All the above are decisive factors when choosing what mapping framework to use.
Below I am going to list some Java frameworks/libraries along-side a few of their basic characteristics. There characteristics are:
Type: The basic underlying mechanism used by the framework
License: What software license it uses
Configuration: What are the supported ways the framework may be configured
GH Stars: GitHub stars. It can loosely interpreted as an indication of the popularity of the framework.
First Release: Older release version and year found in maven repository.
Last Release: Newest release version and year found in maven repository (at the time of writing this article).
The first and last release may be used as an indicator regarding if the project is active or not and how mature it is.
| NAME | TYPE | LICENSE | CONFIGU- RATION | GH STARS | FIRST RELEASE | LAST RELEASE |
|---|---|---|---|---|---|---|
Byte-code instrumentation |
GPLv3 |
Java API |
11 |
1.0 (2014) |
1.0.2 (2017) |
|
Reflection |
Apache 2.0 |
Java API |
187 |
1.0 (2005) |
1.9.4 (2019) |
|
Reflection |
Apache 2.0 |
Java API - Annotations |
151 |
1.1.19 (2019) |
1.7.6 (2021) |
|
Byte-code instrumentation |
MIT |
Java API |
33 |
0.9.0 (2019) |
1.5.0 (2020) |
|
Reflection |
Apache 2.0 |
XML - Annotations |
1.8k |
2.0.1 (2006) |
6.5.0 (2019) |
|
Byte-code instrumentation |
Apache 2.0 |
Java API - XML - Annotations |
155 |
1.1.0 (2012) |
1.6.0.1 (2016) |
|
Static code generation |
Apache 2.0 |
Java API and Annotations |
3.6k |
1.0.0 (2013) |
1.4.1 (2020) |
|
Byte-code instrumentation |
Apache 2.0 |
Java API |
1.7k |
0.3.1 (2011) |
2.3.9 (2020) |
|
Reflection |
BSD |
Java API - Annotations |
25 |
2.0 (2014) |
2.1.0 (2018) |
|
Byte-code instrumentation |
Apache 2.0 |
Groovy |
40 |
1.0.0 (2010) |
1.2 (2020) |
|
Byte-code instrumentation |
Apache 2.0 |
Java API |
1k |
1.0 (2012) |
1.5.4 (2019) |
|
Byte-code instrumentation |
Apache 2.0 |
Java API |
74 |
0.0.3 (2017) |
4.2.5 (2020) |
|
Static code generation |
Apache 2.0 |
Java API and Annotations |
200 |
0.1 (2014) |
1.0 (2017) |
In the next section we are going to benchmark all the above frameworks and see which is the fastest.
The performance test was written using the JMH microbenchmarking framework.
Below, we are going to see a few different cases. In all of them we are going to focus on throughput (mapping operations per second). All the graphs below are in logarithmic scale.
In the benchmark below we are going to map 2 simple objects which contain primitive type fields.
public class SourceSimplePrimitiveObject { private int field1; private boolean field2; private String field3; private char field4; private double field5; // ...getters and setters }
public class TargetSimplePrimitiveObject { private int field1; private boolean field2; private String field3; private char field4; private double field5; // ...getters and setters }

Let’s mark the reflection mappers with red, the static code generation with green and the Byte-code instrumentation with purple.
If we group them in orders of magnitude it would be like that:
10^8 operations: MapStruct, Selma, JMapper
10^7 operations: Nomin
10^6 operations: Orika
10^5 operations: bean-cp, ReMap, BULL, ModelMapper
10^4 operations: Datus, BeanUtils, Dozer, MooMapper
We don’t care about the exact numbers because these may vary per execution of the benchmark and they depend on the capacity of the machine the tests are run on. However, it is important to see the relation of the throughput between each one so we may understand which ones perform better and which not.
|
|
All the mappers used in the above benchmark are producing equivalent objects in an equivalent way. (more on that later) |
public class SourceSimpleArrayObject { private Integer[] array1 = new Integer[1000]; private Boolean[] array2 = new Boolean[1000]; private String[] array3 = new String[1000]; private Character[] array4 = new Character[1000]; private Double[] array5 = new Double[1000]; // ...getters and setters }
public class TargetSimpleArrayObject { private Integer[] array1 = new Integer[1000]; private Boolean[] array2 = new Boolean[1000]; private String[] array3 = new String[1000]; private Character[] array4 = new Character[1000]; private Double[] array5 = new Double[1000]; // ...getters and setters }

If we group them in orders of magnitude it would be like that:
10^5 operations: MapStruct (Shallow), JMapper, Nomin, bean-cp, MapStruct, ReMap, Selma, BULL
10^4 operations: BeanUtils, Datus, MooMapper
10^3 operations: Orika
10^2 operations: ModelMapper
10^1 operations: Dozer
A few surprises here! First of all we see a drop in the order of magnitude compared to the previous benchmark for all the frameworks. This is partially based on the fact that each array contains 1000 entries. So there is much more mapping to be performed per object.
Another surprise is that we see reflection mappers to perform better than Byte-code instrumentation mappers that were better in the previous benchmark.
In this graph you can see that the columns are colored differently and
that a new entry MapStruct (Shallow) was introduced.
|
|
All the mappers produce equivalent objects but not in an
equivalent way. The blue ones are making a shallow copy of the Array
while the red ones are creating a new Array object. |
The MapStruct (Shallow) uses a bit of custom mapping code to produce a mapper
which makes a shallow copy. It will be included also in the next benchmarks
as a comparison of how expensive it is to create new objects instead of re-using
them.
Have in mind that in general the blue mappers which make the shallow copy have a competitive advantage in terms of speed against the red ones which create 5 new objects per mapping.
Both outcomes may be equivalent but they are not the same. Most of the times making shallow copies is enough but some times it may produce undesired behavior and obscure bugs.
Ideally, I would like to compare mappers that produce the result object the same way but this may not be configurable in some mappers and it requires special configuration. So, I have decided to continue like that.
In the next benchmarks I am going to present the results in a similar way.
public class SourceSimpleListObject { private List<Integer> list1 = new ArrayList<>(); private List<Boolean> list2 = new ArrayList<>(); private List<String> list3 = new ArrayList<>(); private List<Character> list4 = new ArrayList<>(); private List<Double> list5 = new ArrayList<>(); // ...getters and setters }
public class TargetSimpleListObject { private List<Integer> list1 = new ArrayList<>(); private List<Boolean> list2 = new ArrayList<>(); private List<String> list3 = new ArrayList<>(); private List<Character> list4 = new ArrayList<>(); private List<Double> list5 = new ArrayList<>(); // ...getters and setters }
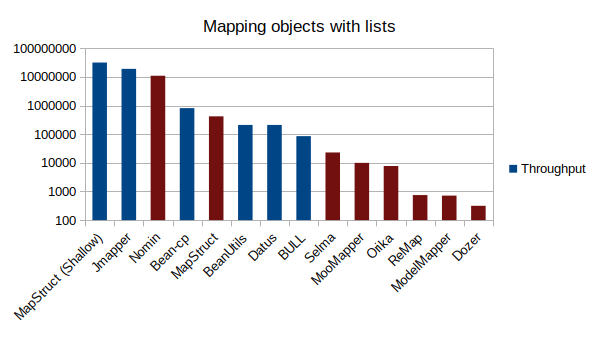
|
|
Like before in the graph the blue ones are making a shallow copy of the lists while the red ones are creating a new object. |
10^7 operations: MapStruct (Shallow), JMapper, Nomin
10^5 operations: bean-cp, MapStruct, BeanUtils, Datus
10^4 operations: BULL, Selma
10^3 operations: MooMapper, Orika
10^2 operations: ReMap, ModelMapper, Dozer
In this benchmark it becomes obvious the difference in performance caused by the shallow copy when we compare the 2 different implementations of the MapStruct mapper.
Again, we see reflection mappers being faster than static code generation or Byte-code instrumentation ones. This is explained though by the shallow copy behavior.
Considering that, I think that this benchmark is consistent with the first one. Under the circumstances only ReMap and ModelMapper performed worse than what I would expect.
I am not sure why this is happening. An assumption is that these mappers do not handle these specific cases optimally and maybe they depend more on reflection than they should.
public class SourceComplexObject { private SourceSimpleObject simpleObject; private SourceSimpleListObject listObject; private Date date; private BigInteger number; // ...getters and setters }
public class TargetComplexObject { private TargetSimplePrimitiveObject simpleObject; private TargetSimpleListObject listObject; private Date date; private BigInteger number; // ...getters and setters }
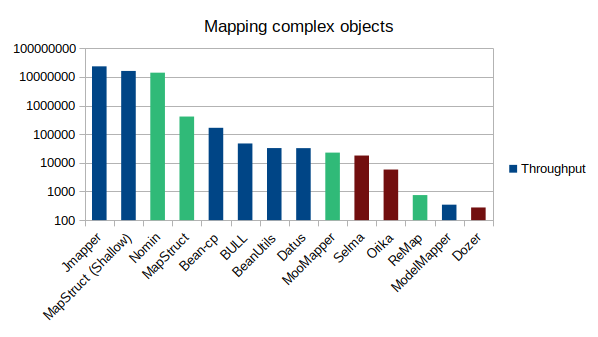
|
|
In the graph the blue ones are making a shallow copy of both the List and the Date object. The green ones are making a shallow copy only of the Date object. The red ones don’t make a shallow copy of any of these 2 cases. |
10^7 operations: JMapper, MapStruct (Shallow), Nomin
10^5 operations: MapStruct, bean-cp
10^4 operations: BULL, BeanUtils, Datus, MooMapper, Selma
10^3 operations: Orika
10^2 operations: ReMap, ModelMapper, Dozer
Generally, the results of this test are the expected and aligned with the previous benchmark.
Again, we see that with the very basic configuration the way each mapper works may significantly vary.
In this section I would like to compare the produced results with a few other publicly available benchmarks:
Benchmark by Baeldung (explained in this article)
Benchmark by Antoine Ray (explained in this article written in French)
There are differences of my results and the results of the other benchmarks.
Bare in mind that:
We are mapping different objects
We are using different configuration for our mappers
10^5 operations: MapStruct, JMapper
10^3 operations: Orika
10^2 operations: ModelMapper, Dozer
10^4 operations: JMapper, MapStruct
10^2 operations: Orika
10^1 operations: ModelMapper, Dozer
Based on the analysis we had about how mappers work these are perfectly expected results. I think generally they agree with my benchmark.
JMapper and MapStruct had the best performance as they did in my benchmarks. Orika was an order of magnitude faster than ModelMapper and Dozer. Only in my first benchmark Orika performed a bit better. Dozer is always last.
|
|
The Baeldung’s benchmark does not include tests to verify how the mapping is performed but I have performed a few tests and it seems that the produced objects are equivalent and mapped in an equivalent way. So, the relation of the performance of each compared mapping frameworks is clear. |
10^7 operations: MapStruct, Selma, Manual, JMapper
10^6 operations: Datus, Orika
10^5 operations: ModelMapper, BULL
10^4 operations: Dozer
|
|
This benchmark also produces equivalent objects and the mapping is performed in an equivalent way. |
Finally, a benchmark that agrees with my initial analysis even more than my own! :P
Considering the various shallow copy cases it is very close to my findings. The only significant differences I can see is the ModelMapper which performed significantly better than my benchmark and BULL which performed a bit worse than in my benchmark.
Others may vary but I believe we can blame the shallow copy behavior for the difference.
Another significant difference is that in this benchmark a realistic DTO is constructed. For example there are fields that use different names on source and target object and the object graph of the source and target object differs. For that reason this benchmark uses functionality of the mappers that mine didn’t touch.
This also could explain some of the deviations of this benchmark with mine.
In general however I feel that there is common ground and the outcome is justified.
Finally, I find this benchmark closest to the day to day scenarios one will have to face. So, it is a very good tool to help someone select a performant mapping framework.
|
|
Both these benchmarks avoid in their source/destination objects List or
Array of primitive wrapper classes. Also they do not include objects such as
Date which is unclear how to be mapped and except for primitive types or
primitive wrapper classes the destination classes are different than the
source ones. This way they don’t fall into the pitfall of mapping in a
nonequivalent way. |
I remember the first time I needed a mapper in a professional setting I asked around the other colleagues to see what they were using. What they did at that time was to use a simple custom mapper or perform manual mapping.
In general, I am reluctant to use/implement custom solutions for problems that are obviously common and most probably are already addressed by existing open-source software. So, I did what everyone would do.. I googled it! One of the first results was by StackOverflow and it was this.
The most up-voted answer was suggesting the Dozer mapping framework. So, I used that one.
Mapping objects that had their fields named the same was very easy and was offered out of the box. From time to time I may had to perform a bit more complex mapping. I suffer from a severe XML allergy but even I could configure Dozer to perform the mapping I would like to do. Other times I preferred to manually map the few fields that Dozer could not handle (or wasn’t trivial to handle) and that was OK. Unfortunately, Dozer offers very limited annotation support, for example back then it wasn’t possible to exclude a field from being mapped with annotations.
In general I was pretty happy though.
However, as you know by know Dozer performs poorly compared to other frameworks.
To be honest, even in projects that heavy mapping is involved I don’t think that the performance of the mapper will get noticed compared to other causes of bad performance such as the database related stuff.
On the other hand we must admit that using a faster mapping framework is like having a better CPU for free. It doesn’t make sense to me to use a slow framework except only if it offers some functionality which isn’t otherwise achievable.
Even then, I find more sane to use 2 mapping frameworks. A fast one for everything and a slower one only for the cases which is absolutely required.
Since my first encounter with Dozer I had come across it again in other jobs and projects. I blame 2 things for that. First, it is an old and well established framework. People known it and are already familiar with it. It is the second project with the most GitHub stars from the ones mentioned after all! Many existing projects from the 2000s will probably use it. Second, I blame the above StackOverflow’s question and most up-voted answer for this! Even now if someone searches for a mapping framework this answer may pop up!
Ignorance will lead to poor performance that will go probably unnoticed for ever wasting electric power and producing C2O!
Having said all that I strongly suggest to select one of the fast mapping frameworks.
Other than that it is a matter of taste (i.e. XML vs Annotation configuration) and specific requirements (i.e. lack of setters/getters, support for Generics, mapping of objects loaded at runtime etc.). A quick reading of the documentation will give you an idea about each framework’s API. You will have to try it yourself in order to see what suits you best.
I am personally a bit biased against projects that seem unpopular or abandoned. If a project is abandoned at the very least it means that if a feature that you would like to have is missing it won’t probably get implemented in the upstream and if a security issue is found a new version may come late or not at all.
Personally, I currently use MapStruct and I am very happy. I like the API. It is easy to configure the mapping of the fields or combine manual mapping if required. Also, it is easy to understand how the mapping is performed and debug it if required. Furthermore, it seems reasonably active and feature-rich.
Mapping is not free. Double check if you really need it before going with it!
Manual mapping is not so bad. No shame there! Go with it if you feel like it. It has good performance, it does not need extra dependencies, it clearly shows the intention of how the mapping should work and it doesn’t require extra knowledge. However, if you find yourself writing all the time boilerplate mapping code then seriously consider using a mapper and think of it as an investment in productivity for the future!
Re-inventing the wheel requires a lot of effort and hides many caveats. Go with well established solutions!
Correctness of the program is more important than performance! Make sure to write (explicit or implicit) tests for your mappings! First of all you may have configured the mapper wrong. Then, the mapper may not work the way you expect it to work. In case you are switching mapping frameworks, let’s say from a slow one to a faster one, make sure to write tests that ensure that the new mapper works the same way as the old one.
Avoid using slow mappers! Use the faster, environment friendly ones!
In case you need functionality that is only offered by a slower mapper consider using the slow mapper only for the specific cases it is required and not for every mapping in the application!
In case you have very special performance requirements make sure to write your own benchmark that tests exactly the case that you are interested in. All the above benchmarks are indicative.
I hope you found this article interesting and had as much fun reading it as I had writing it!
Finally, a big thanks to all the open source contributors that have dedicated so much of their time in creating all these beautiful tools!
|
|
If you think that I have misjudged a mapper due to bad configuration and my benchmark is not objective feel free to provide a patch. |

Designed by Periklis Ntanasis



